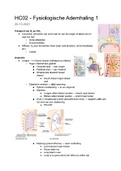
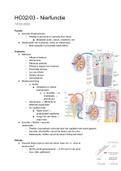
Speech and Language Processing
REGULIERE EXPRESSIES
Chapter 2 - Regular Expressions and Automata
2.1 Regular Expressions
A regular expression is a formula in a special language that specifies simple classes of
strings. A string is a sequence of symbols. Regular expression search requires a pattern
that we want to search for and a corpus of texts to search through. When we give a
search pattern, we assume that the search engine returns the line of the document
returned.
2.1.1 Basic Regular Expression Patterns
// Begin and end of a regular expression. REs are case sensitive.
[ ] Specifies a disjunction of characters to match
- Range of characters, e.g. [A-Z]
^ What a character cannot be, when in the brackets, e.g. [^a]
? The preceding character or nothing
* The Kleene *, zero or more occurrences of the immediately previous character or
regular expression
+ The Kleene +, one or more of the previous character
. Wildcard, any single character (except a carriage return)
/.*/ Any string of characters
Anchors are special characters that anchor regular expressions to particular places in a
string:
^ /^The/ means it will only match The at the start of a line
$ Matches the end of a line
\b Matches a word boundary
\B Matches a non-boundary
2.1.2 Disjunction, Grouping, and Precedence
| Disjunction, also called pipe symbol
() Causes precedence
Operator precedence hierarchy:
Parenthesis ()
Counters +*?{}
Sequences and anchors the ^my end$
Disjunction |
We say patterns are greedy, expanding to cover as much of a string as they can.
2.1.3
False positives: strings that we incorrectly matched
False negatives: strings that we incorrectly missed
2.1.5 Advanced Operators
{3} Exactly 3 occurrences of the previous character or expression
,{n, m} from n to m occurrences of the previous char or expression
{n, } at least n occurrences of the previous char or expression
\n newline
\t tab
For the special characters, use \ to use them as themselves.
2.1.6 Regular Expression Substitution, Memory and ELIZA
An importent use of regular expressions is in substitutions.
<\1> Number operator to refer back.To refer to the integer we’ve found so that we can
easily add the brackets.
Registers: numbered memories. This memory feature is not part of every regular
expression language and is often considered an “extended” feature of regular
expressions.
FORMELE TALEN I
2.2 Finite-State Automata
A RE is one way of describing a finite-state automation (FSA). Second, a RE is one way
of characterising a particular kind of formal language called a regular language.
2.2.1 Use of an FSA to Recognise Sheeptalk
An automaton for modelling a RE, also called FSA, recognises a set of strings. The
automaton has different states, which are represented by nodes. State 0 is the start
state. The last state is the final state or accepting state, which we represent by the
double circle. It also has transitions, which we represent by arcs in the graph. Think of
the input as being written on a long tape broken up into cells, with one symbol written in
each cell of the tape. If some input doesn’t match an arc, or if it just happens to get stuck
in some non-final state, we say the machine rejects or fails to accept an input. We can
also represent an automaton with a state-transition table.
A finite automaton is defined by the following 5 parameters:
Q = q0, q1, A finite set of N states
q2….qN-1
Σ A finite input alphabet of symbols
q0 the start state
F the set of final states, F Q
δ(q,i) the transition function or transition matrix between states. Given a state q
relation from Q x Σ to Q
A deterministic algorithm is one that has no choice points; the algorithm always knows
what to do for any input. We can think of “empty” elements in the table as if they all
pointed at one “ empty” state, which we might call the fail state or sink state.
,2.2.2 Formal Languages
Formal language: a model that van both generate and recognise all and only the strings of
a formal language acts as a definition of the formal language. A formal language is a set
of strings, each string composed of symbols from a finite set called an alphabet. Formal
languages are not the same as natural languages, which are the languages that real
people speak. The term generative grammar is sometimes used in linguistics to mean a
grammar of a formal language.
2.2.4 Non-Deterministic FSAs
Automata with decision points are called non-deterministic FSAs (NFSAs). A
deterministic automation is one whose behaviour during recognition is fully determined
by the state it is in and the symbol it is looking at (DFSA). Another common type of non-
determinism is one caused by arcs that have no symbols on them, called ε-transitions.
2.3 Regular Languages and FSAs
The class if languages that are definable by regular expressions is exactly the same as the
class of languages that are characterisable by finite-state automata. We therefore call
these languages the regular languages. The class of regular languages (or regular sets)
over Σ is formally defined as follows:
1. ∅ is a regular language
2. a Σ ε, {a} is a regular language
3. If L1 and L2 are regular languages, then so are:
1. L1 * L2 = {xy | x L1, y L2}, the concatenation of L1 and L2
2. L1 L2, the union or disjunction of L1 and L2
3. L1*, the Kleene closure of L1
Any regular expression can be turned into a (perhaps larger) expression that only makes
use of the three primitive operations.
REs are also closed under the following operations:
Intersection: if L1 and L2 are regular languages, then so is L1 L2, the language
consisting of the set of strings that are in both L1 and L2
Difference: If L1 and L2 are regular languages, then so is L1 - L2, the language consisting
of the set of strings that are in L1 but not L2
Complementation: if L1 is a regular language, then so is Σ* - L1, the set of all possible
strings that aren’t in L1 (Σ* means the infinite set of all possible strings formed from the
alphabet Σ)
Reversal: If L1 is a regular language, then so is L1R, the language consisting of the set of
reversals of all the strings in L1
Showing that an automaton can be built for each regular language and, conversely, that
a regular language can be built for each automaton. For the inductive step, we show that
each of the primitive operations of a regular expression can be imitated by an automaton:
Concatenation: we string two FSAs next to each other by connecting all the final
states of FSA1 to the initial state of FSA2 by an ε-transition.
Closure: We create a new final and initial state, connect the original final states of
the FSA back to the initial states by ε-transitions, and then put direct links between
the new initial and final states by ε-transitions.
, Union: We add a single new initial state q’0, and add new ε-transitions from it to the
former initial states of the two machines to be joined.
MORFOLOGIE
Chapter 3 - Words and Transducers
3.1 Survey of (Mostly) English Morphology
Morphology is the study of the way words are built up from smaller meaning-bearing units,
morphemes. A morpheme is often defined as the minimal meaning-bearing unit in a
language. It is useful to distinguish two broad classes of morphemes: stems and affixes.
The stem is the “main” morpheme of the word, supplying the main meaning, and the
affixes add “additional” meanings of various kinds. Affixes are further divided into prefixes,
suffixes, infixes, and circumfixes. Prefixes precede the stem, suffixes follow the
stem, circumfixes do both, and infixes are inserted inside the stem. A word can have more
than one affix. Languages that tend to string affixes together, as Turkish does, are called
agglutinative languages.
There are many ways to combine morphemes to create words:
Inflection is the combination of a word stem with a grammatical morpheme, usually
resulting in a word of the same class as the original stem and usually filling some
syntactic function like agreement.
Derivation is the combination of a word stem with a grammatical morpheme, usually
resulting in a word of a different class, often with a meaning hard to predict exactly.
Compounding is the combination of multiple word stems together
Cliticization is the combination of a word stem with a clitic. A clitic is a morpheme
that acts syntactically like a word but is reduced in form and attached to another
word.
3.1.1 Inflectional Morphology
English nouns have only two kinds of inflection: an affix that marks plural and an affix that
marks possessive. English has three kinds of verbs; main verbs (eat, sleep), modal
verbs (can, will), and primary verbs (be, have, do). Of the main and primary verbs (these
have inflectional endings), a large class are regular, that is, all verbs of this class have the
same endings marking the same functions. Regular verbs and forms are significant in the
morphology of English: first, because they cover a majority of the verbs; and second,
because the regular class is productive. A productive class is one that automatically
includes any new words that enter the language. The irregular verbs are those that have
some more or less idiosyncratic forms of inflection. Note that an irregular verb can inflect in
the past form (also called preterite) by changing its vowel (eat/ate), its vowel and some
consonants (catch/caught), or with no change at all (cut/cut).
The -ing participle is used in the progressive construction to mark present or
ongoing activity or when the vern is treated as a noun; this latter kind of nominal use of a
verb is called a gerund. The -ed/-en participle is used in the perfect construction or the
passive construction. A number of regular spelling changes occur at these morpheme
boundaries (beg/begging/begged).
3.1.2 Derivational Morphology
A common end of derivation in English is the formation of new nouns, often from verbs or
adjectives. This process is called nominalization (computerize —> computerization).
REGULIERE EXPRESSIES
Chapter 2 - Regular Expressions and Automata
2.1 Regular Expressions
A regular expression is a formula in a special language that specifies simple classes of
strings. A string is a sequence of symbols. Regular expression search requires a pattern
that we want to search for and a corpus of texts to search through. When we give a
search pattern, we assume that the search engine returns the line of the document
returned.
2.1.1 Basic Regular Expression Patterns
// Begin and end of a regular expression. REs are case sensitive.
[ ] Specifies a disjunction of characters to match
- Range of characters, e.g. [A-Z]
^ What a character cannot be, when in the brackets, e.g. [^a]
? The preceding character or nothing
* The Kleene *, zero or more occurrences of the immediately previous character or
regular expression
+ The Kleene +, one or more of the previous character
. Wildcard, any single character (except a carriage return)
/.*/ Any string of characters
Anchors are special characters that anchor regular expressions to particular places in a
string:
^ /^The/ means it will only match The at the start of a line
$ Matches the end of a line
\b Matches a word boundary
\B Matches a non-boundary
2.1.2 Disjunction, Grouping, and Precedence
| Disjunction, also called pipe symbol
() Causes precedence
Operator precedence hierarchy:
Parenthesis ()
Counters +*?{}
Sequences and anchors the ^my end$
Disjunction |
We say patterns are greedy, expanding to cover as much of a string as they can.
2.1.3
False positives: strings that we incorrectly matched
False negatives: strings that we incorrectly missed
2.1.5 Advanced Operators
{3} Exactly 3 occurrences of the previous character or expression
,{n, m} from n to m occurrences of the previous char or expression
{n, } at least n occurrences of the previous char or expression
\n newline
\t tab
For the special characters, use \ to use them as themselves.
2.1.6 Regular Expression Substitution, Memory and ELIZA
An importent use of regular expressions is in substitutions.
<\1> Number operator to refer back.To refer to the integer we’ve found so that we can
easily add the brackets.
Registers: numbered memories. This memory feature is not part of every regular
expression language and is often considered an “extended” feature of regular
expressions.
FORMELE TALEN I
2.2 Finite-State Automata
A RE is one way of describing a finite-state automation (FSA). Second, a RE is one way
of characterising a particular kind of formal language called a regular language.
2.2.1 Use of an FSA to Recognise Sheeptalk
An automaton for modelling a RE, also called FSA, recognises a set of strings. The
automaton has different states, which are represented by nodes. State 0 is the start
state. The last state is the final state or accepting state, which we represent by the
double circle. It also has transitions, which we represent by arcs in the graph. Think of
the input as being written on a long tape broken up into cells, with one symbol written in
each cell of the tape. If some input doesn’t match an arc, or if it just happens to get stuck
in some non-final state, we say the machine rejects or fails to accept an input. We can
also represent an automaton with a state-transition table.
A finite automaton is defined by the following 5 parameters:
Q = q0, q1, A finite set of N states
q2….qN-1
Σ A finite input alphabet of symbols
q0 the start state
F the set of final states, F Q
δ(q,i) the transition function or transition matrix between states. Given a state q
relation from Q x Σ to Q
A deterministic algorithm is one that has no choice points; the algorithm always knows
what to do for any input. We can think of “empty” elements in the table as if they all
pointed at one “ empty” state, which we might call the fail state or sink state.
,2.2.2 Formal Languages
Formal language: a model that van both generate and recognise all and only the strings of
a formal language acts as a definition of the formal language. A formal language is a set
of strings, each string composed of symbols from a finite set called an alphabet. Formal
languages are not the same as natural languages, which are the languages that real
people speak. The term generative grammar is sometimes used in linguistics to mean a
grammar of a formal language.
2.2.4 Non-Deterministic FSAs
Automata with decision points are called non-deterministic FSAs (NFSAs). A
deterministic automation is one whose behaviour during recognition is fully determined
by the state it is in and the symbol it is looking at (DFSA). Another common type of non-
determinism is one caused by arcs that have no symbols on them, called ε-transitions.
2.3 Regular Languages and FSAs
The class if languages that are definable by regular expressions is exactly the same as the
class of languages that are characterisable by finite-state automata. We therefore call
these languages the regular languages. The class of regular languages (or regular sets)
over Σ is formally defined as follows:
1. ∅ is a regular language
2. a Σ ε, {a} is a regular language
3. If L1 and L2 are regular languages, then so are:
1. L1 * L2 = {xy | x L1, y L2}, the concatenation of L1 and L2
2. L1 L2, the union or disjunction of L1 and L2
3. L1*, the Kleene closure of L1
Any regular expression can be turned into a (perhaps larger) expression that only makes
use of the three primitive operations.
REs are also closed under the following operations:
Intersection: if L1 and L2 are regular languages, then so is L1 L2, the language
consisting of the set of strings that are in both L1 and L2
Difference: If L1 and L2 are regular languages, then so is L1 - L2, the language consisting
of the set of strings that are in L1 but not L2
Complementation: if L1 is a regular language, then so is Σ* - L1, the set of all possible
strings that aren’t in L1 (Σ* means the infinite set of all possible strings formed from the
alphabet Σ)
Reversal: If L1 is a regular language, then so is L1R, the language consisting of the set of
reversals of all the strings in L1
Showing that an automaton can be built for each regular language and, conversely, that
a regular language can be built for each automaton. For the inductive step, we show that
each of the primitive operations of a regular expression can be imitated by an automaton:
Concatenation: we string two FSAs next to each other by connecting all the final
states of FSA1 to the initial state of FSA2 by an ε-transition.
Closure: We create a new final and initial state, connect the original final states of
the FSA back to the initial states by ε-transitions, and then put direct links between
the new initial and final states by ε-transitions.
, Union: We add a single new initial state q’0, and add new ε-transitions from it to the
former initial states of the two machines to be joined.
MORFOLOGIE
Chapter 3 - Words and Transducers
3.1 Survey of (Mostly) English Morphology
Morphology is the study of the way words are built up from smaller meaning-bearing units,
morphemes. A morpheme is often defined as the minimal meaning-bearing unit in a
language. It is useful to distinguish two broad classes of morphemes: stems and affixes.
The stem is the “main” morpheme of the word, supplying the main meaning, and the
affixes add “additional” meanings of various kinds. Affixes are further divided into prefixes,
suffixes, infixes, and circumfixes. Prefixes precede the stem, suffixes follow the
stem, circumfixes do both, and infixes are inserted inside the stem. A word can have more
than one affix. Languages that tend to string affixes together, as Turkish does, are called
agglutinative languages.
There are many ways to combine morphemes to create words:
Inflection is the combination of a word stem with a grammatical morpheme, usually
resulting in a word of the same class as the original stem and usually filling some
syntactic function like agreement.
Derivation is the combination of a word stem with a grammatical morpheme, usually
resulting in a word of a different class, often with a meaning hard to predict exactly.
Compounding is the combination of multiple word stems together
Cliticization is the combination of a word stem with a clitic. A clitic is a morpheme
that acts syntactically like a word but is reduced in form and attached to another
word.
3.1.1 Inflectional Morphology
English nouns have only two kinds of inflection: an affix that marks plural and an affix that
marks possessive. English has three kinds of verbs; main verbs (eat, sleep), modal
verbs (can, will), and primary verbs (be, have, do). Of the main and primary verbs (these
have inflectional endings), a large class are regular, that is, all verbs of this class have the
same endings marking the same functions. Regular verbs and forms are significant in the
morphology of English: first, because they cover a majority of the verbs; and second,
because the regular class is productive. A productive class is one that automatically
includes any new words that enter the language. The irregular verbs are those that have
some more or less idiosyncratic forms of inflection. Note that an irregular verb can inflect in
the past form (also called preterite) by changing its vowel (eat/ate), its vowel and some
consonants (catch/caught), or with no change at all (cut/cut).
The -ing participle is used in the progressive construction to mark present or
ongoing activity or when the vern is treated as a noun; this latter kind of nominal use of a
verb is called a gerund. The -ed/-en participle is used in the perfect construction or the
passive construction. A number of regular spelling changes occur at these morpheme
boundaries (beg/begging/begged).
3.1.2 Derivational Morphology
A common end of derivation in English is the formation of new nouns, often from verbs or
adjectives. This process is called nominalization (computerize —> computerization).