Statistisch redeneren werkgroepen:
WG1
Hoogste waarde = verwachte waarde dus dat is waarschijnlijk ook de waarde in de populatie.
Hoe kunnen we een uitspraak doen over de populatie op basis van de steekproef wat hebben
we daarvoor nodig steekproeven verdeling
Met de steekproeven verdeling kan je zien of de steekproef representatief is van de populatie,
en dus aan de hand daarvan kan je kijken.
Verwachte waarde = gelijk aan de waarde van de populatie = Parameter
Sampling distribution = het gemiddelde van het gemiddelde
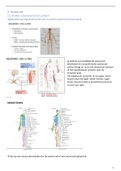
Want: Sampling Distribution (middelste grafiek): De rode gestippelde lijn hier geeft het
gemiddelde van de steekproeven weer. Dit is de grafiek die een "gemiddelde van
gemiddelden" weergeeft. Dit komt omdat elke steekproef een eigen gemiddelde heeft, en de
rode gestippelde lijn het gemiddelde van deze steekproefgemiddelden is.
Sample Distribution (onderste grafiek): Deze grafiek toont de gewichten van individuele
snoepjes binnen een enkele steekproef. De rode gestippelde lijn is het gemiddelde gewicht
van de snoepjes in deze specifieke steekproef, wat geen "gemiddelde van gemiddelden" is.
Population Distribution (bovenste grafiek): De rode gestippelde lijn in deze grafiek is het
gemiddelde van de volledige populatie, gebaseerd op de kansverdeling van het gewicht van de
snoepjes in de populatie.
Vraag 7 werkgroep opdracht uitleg:
Hoe maak je van een steekproeven verdeling een kansverdeling? Door op de y-as
proporties (kansen) toe te voegen (stonden eerst aantallen)
Unbiased estimator = gemiddeldes, standaarddeviaties, medianen zuivere schatters van de
populatie waarde op basis van steekproef uitspraak doen over alle snoepjes in de fabriek.
, Steekproef 10 snoepjes en er zitten 2 gele in, betekent niet dat de hele fabriek maar 2 snoepjes
zitten biased estimator schatter waar je geen uitspraak mee kan doen.
Hoe bereken je gemiddelde aan de hand van steekproevenverdeling?
- De staarten van de verdeling moeten gelijk zijn
- Getallen + elkaar en delen door 2
Hoorcollege 2 kansmodellen:
Waarom kansmodellen nodig?
- We moeten een manier hebben om de steekproevenverdeling overbodig te maken want
dat kost heel veel tijd, energie en geld.
Exact approach:
- Exact berekenen wat de kansen zijn
- Doel steekproeven overbodig maken
- Grenzen stellen
- ALLEEN BIJ DISCRETE WAARDEN
Voorbeeld:
Je gooit 2x met een muntje. Dan zijn er 4 mogelijke uitkomsten.
De kans kan je berekenen door de product regel:
Kansen vermenigvuldigen met elkaar.
Normaalverdeling = kans op continue schaal
Binominaal verdeling = discrete schaal
Steekproevenverdeling meerdere steekproeven
Hoe relevanter het onderzoek is hoe hoger de stakes zijn, dus dan wil je kritischer zijn
hierdoor pas je je significantieniveau aan beslisregel
Bootstrapping:
- Je trekt 1 steekproef en uit die steekproef neem je nieuwe steekproef
- Om als doel = steekproevenverdeling maken
- Met teruglegging
- Dat doe je het aantal keer wat het formaat van de sample
Is dit representatief voor de populatie?
- Op een grote sample is het nauwkeuriger meer representatief voor de populatie
95% betrouwbaarheidsinterval = 95% van de observaties vallen binnen de intervallen.
Theoretische benadering van de steekproevenverdeling:
Continue kansverdeling =
- Totale oppervlakte onder de verdeling is altijd 1
WG1
Hoogste waarde = verwachte waarde dus dat is waarschijnlijk ook de waarde in de populatie.
Hoe kunnen we een uitspraak doen over de populatie op basis van de steekproef wat hebben
we daarvoor nodig steekproeven verdeling
Met de steekproeven verdeling kan je zien of de steekproef representatief is van de populatie,
en dus aan de hand daarvan kan je kijken.
Verwachte waarde = gelijk aan de waarde van de populatie = Parameter
Sampling distribution = het gemiddelde van het gemiddelde
Want: Sampling Distribution (middelste grafiek): De rode gestippelde lijn hier geeft het
gemiddelde van de steekproeven weer. Dit is de grafiek die een "gemiddelde van
gemiddelden" weergeeft. Dit komt omdat elke steekproef een eigen gemiddelde heeft, en de
rode gestippelde lijn het gemiddelde van deze steekproefgemiddelden is.
Sample Distribution (onderste grafiek): Deze grafiek toont de gewichten van individuele
snoepjes binnen een enkele steekproef. De rode gestippelde lijn is het gemiddelde gewicht
van de snoepjes in deze specifieke steekproef, wat geen "gemiddelde van gemiddelden" is.
Population Distribution (bovenste grafiek): De rode gestippelde lijn in deze grafiek is het
gemiddelde van de volledige populatie, gebaseerd op de kansverdeling van het gewicht van de
snoepjes in de populatie.
Vraag 7 werkgroep opdracht uitleg:
Hoe maak je van een steekproeven verdeling een kansverdeling? Door op de y-as
proporties (kansen) toe te voegen (stonden eerst aantallen)
Unbiased estimator = gemiddeldes, standaarddeviaties, medianen zuivere schatters van de
populatie waarde op basis van steekproef uitspraak doen over alle snoepjes in de fabriek.
, Steekproef 10 snoepjes en er zitten 2 gele in, betekent niet dat de hele fabriek maar 2 snoepjes
zitten biased estimator schatter waar je geen uitspraak mee kan doen.
Hoe bereken je gemiddelde aan de hand van steekproevenverdeling?
- De staarten van de verdeling moeten gelijk zijn
- Getallen + elkaar en delen door 2
Hoorcollege 2 kansmodellen:
Waarom kansmodellen nodig?
- We moeten een manier hebben om de steekproevenverdeling overbodig te maken want
dat kost heel veel tijd, energie en geld.
Exact approach:
- Exact berekenen wat de kansen zijn
- Doel steekproeven overbodig maken
- Grenzen stellen
- ALLEEN BIJ DISCRETE WAARDEN
Voorbeeld:
Je gooit 2x met een muntje. Dan zijn er 4 mogelijke uitkomsten.
De kans kan je berekenen door de product regel:
Kansen vermenigvuldigen met elkaar.
Normaalverdeling = kans op continue schaal
Binominaal verdeling = discrete schaal
Steekproevenverdeling meerdere steekproeven
Hoe relevanter het onderzoek is hoe hoger de stakes zijn, dus dan wil je kritischer zijn
hierdoor pas je je significantieniveau aan beslisregel
Bootstrapping:
- Je trekt 1 steekproef en uit die steekproef neem je nieuwe steekproef
- Om als doel = steekproevenverdeling maken
- Met teruglegging
- Dat doe je het aantal keer wat het formaat van de sample
Is dit representatief voor de populatie?
- Op een grote sample is het nauwkeuriger meer representatief voor de populatie
95% betrouwbaarheidsinterval = 95% van de observaties vallen binnen de intervallen.
Theoretische benadering van de steekproevenverdeling:
Continue kansverdeling =
- Totale oppervlakte onder de verdeling is altijd 1