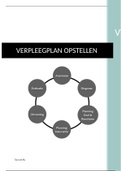
Hoorcollege 1 survey
*Fouten*
Wanneer we een survey maken stellen we veel vragen aan individuele personen (de personen zelf
boeien ons niet persoonlijk). De antwoorden die zij geven zijn niet per se boeiend. We willen vooral
weten of iets iets over de populatie zegt.
Target audience niet de volledige populatie die bestaat, maar de populatie waar JIJ iets over
zeggen wil!
Bij surveys interviewen we NOOIT iedereen. We interviewen gewoon een random aantal mensen
binnen de populatie.
Voorbeeldsituatie: populatie in de hoorcollegezaal; “hoe vinden jullie de les tot nu toe?”.
De voorste rij is niet representatief als ‘deel’populatie, want er kunnen bijvoorbeeld mensen vooraan
zitten omdat ze en te laat zijn en die de les sowieso niet leuk vinden. Echter kunnen er ook mensen
tussen zitten die juist de les leuk vinden.
Er kan dan bias ontstaan;
- Systematisch positieve bias
- Systematisch negatieve bias
We willen in de survey geen random error en we willen geen bias!
Random error (willekeurige fout) Men weet niet wat je als individueel persoon denkt maar
‘overall’ wordt er verwacht dat er een goede schatting van je mening kan worden gemaakt. Dit kan
niet bij bias; er kan geen goede schatting gemaakt worden van je ‘overall opinion’.
Systematische bias Je bent waarschijnlijk je gemiddelde aan het ‘overestimaten’ of
‘underestimaten’, dus je schat je gemiddelde hoger dan dat het zou moeten zijn of je schat je
gemiddelde lager.
Beide fouten geven je wel wat inzicht, maar het hangt ervan af wat het is en wat het doet.
Random error steekproef is niet representatief
Systematic error bias je geeft een antwoord op een vraag, maar het antwoord is geen goede
reflectie van de status van je echte antwoord.
Beetje vaag, maar stel je vraagt aan iemand: ‘heb je dit gedaan?’ en iemand zegt ‘ja’ maar
het daadwerkelijke antwoord is ‘nee’, dan is er sprake van systematische error bias.
OF Iemand stelt een complexe vraag en je wil het goede antwoord geven, maar je weet niet
hoe! We gaan er dan vanuit dat de gegeven antwoorden representatief zijn voor de
populatie, maar in werkelijkheid is dit niet zo. De fouten zijn dan random verschillend of
systematisch verschillend.
Dusssssss….. kleine samenvatting!
- We hebben random errors, oftewel willekeurige fouten
- En we hebben systematische fouten en deze zijn biased (in theorie goede steekproef;
dus representatief; maar we hebben gewoon geen geluk binnen de resultaten (ze zijn
niet representatief))
Random error
- Steekproef fout
- Vragen: (invalide vragen) Invaliditeit, ‘het was een eerlijke fout’
, Stel: je vraagt aan een groep mensen hoeveel liedjes ze per dag luisteren. De ene groep geeft
een te hoog antwoord en een andere een te laag antwoord omdat ze het correcte antwoord
gewoon niet weten. Een andere groep geeft wel het juiste antwoord omdat ze dit laatst
opgezocht hebben. Dan kloppen de resultaten voor het individu niet, maar er valt wel een
schatting te maken over het aantal liedjes over de gehele populatie.
Is dit erg? Nee, niet als je iets wil weten over de gehele populatie.
Systematische bias fout
- Steekproef bias (voorbeeld van de studenten die voorin zitten die bijvoorbeeld ofwel
positief ofwel negatief biased zijn)
- Vragen: bias: ‘heb je dit gedaan?’, antwoord is nee, maar je zegt ja
‘Over rapporteren’, want omdat de leraar het bijvoorbeeld vraagt, wordt er vaker ja
gerapporteerd dan daadwerkelijk zou moeten (social desirability, komt verder nog aan bod).
*De manier waarop je een vraag stelt, of de persoon die vraag stelt heeft invloed op de ‘validity’ van
de antwoorden die je krijgt.*
*Vragen stellen*
Meerdere soort fouten vragen:
- Two barreled questions Er worden eigenlijk twee vragen gesteld binnen een vraag; ‘Is
dit een leuk en interessant vak?’.
- Leidende (BIASED) vragen Vragen die je al een bepaalde richting in sturen; ‘Vind jij
ook dat de vaccinatieplicht afgeschaft moet worden?’.
Veelvoorkomende fouten omtrent vragen in surveys:
- Een vraag die gesteld wordt met de verkeerde woorden
- De manier waarop de vraag gesteld wordt door de interviewer
- Iets wordt niet begrepen door degene die geïnterviewd wordt: hebben mensen
bijvoorbeeld wel de kennis om een vraag te beantwoorden bedenken doelgroep
- De geïnterviewde kan sommige dingen niet meer herinneren
- De manier hoe informatie door de interviewer wordt vastgelegd
- De manier hoe informatie wordt verwerkt; dus de manier hoe antwoorden worden
gecodeerd of hoe data in de computer wordt gezet
- Als je simpele, korte antwoorden wil, moet je de vragen ook simpel houden
‘I don’t know’ – optie
- Je kan er niet zomaar vanuit gaan dat mensen die ‘don’t know’ aanklikken in de survey
random verdeeld worden over de andere factoren. De mensen die dit aanklikken zijn dus
niet gelijk verdeeld over de antwoord opties. Je kan er niet vanuit gaan dat als je de optie
weglaat, je dezelfde verdeling krijgt als wanneer je de optie niet weg zou laten!
- Deze optie wordt vaak gekozen, omdat het een makkelijke optie is. Je hoeft er minder
over na te denken als de vraag wat moeilijker is (dit geldt ook voor de ‘middelcategorie’).
Wie kiest er eigenlijk voor deze optie??
- Iets kan cultureel gevoelig zijn.. Stel iemand stelt een vraag en jij geeft een ander
antwoord dan ‘I don’t know’, omdat je diegene wil helpen, kan dit fout zijn als het echte
antwoord wel ‘I don’t know’ is. Wat ook meeweegt hierbij is of de survey online is of
face-to-face.
- Onderwijsniveau kan invloed hebben in de mate waarmee er met de optie geantwoord
wordt; mensen met een hoog niveau zullen vaker deze optie gebruiken. Ze weten
namelijk vaak wat ze wel en juist niet weten!
, Soms is het handig om een middelcategorie te hebben. Mensen zeggen vaak dat het eigenlijk een
‘geen mening’ optie is. Wanneer je middeloptie in de survey stopt, wordt de ‘don’t know’- optie ook
minder gebruikt.
Don’t know optie wel of niet implementeren in survey????
- Als je wil dat mensen echt een keuze maken (omdat ze ook echt weten welke keuze ze
moeten maken; voorbeeld: poets je je tanden altijd twee keer per dag) NIET;
- Als je wil dat mensen een keuze maken alleen als ze dat ook echt kunnen (soms is het
handig om wel een extra optie in de survey te doen, omdat dit dan een goed antwoord
is) WEL!
Beware:
- Als je geen middeloptie toevoegt, kan er irritatie ontstaan doordat mensen oprecht geen
antwoord hebben op de vraag.
- Middelopties zijn soms ook onvoorspelbaar
*Antwoordopties*
Ordinaal Totally agree, agree, disagree, totally disagree
Ordinaal Agree ……….. Disagree
Maaaaaaaaarrrr… De laatste behandelen we als interval (Het heeft namelijk meer dan zeven
antwoordcategorieen). Je kan namelijk als alle vragen dezelfde karakteristieken hebben; dus allemaal
5 punts-Likertschaal bijvoorbeeld; een variabele maken op intervalniveau.
Ratio Bijvoorbeeld: ‘Hoe vaak ga je naar de bar?’ (voeg hierbij een tijdsperiode toe, dus
bijvoorbeeld ‘per week’ of per maand’ voor meer duidelijkheid).
--->
Ordinaal Als je de antwoordopties verandert in bijvoorbeeld: Nooit – af en toe – regelmatig – vaak
Een antwoordoptie hoeft niet altijd helemaal precies te zijn. Denk hierbij aan het antwoord op de
vraag hoe vaak iemand naar de bar gaat. Bij ander soort vragen kan er wel gebruik gemaakt worden
van een meer preciezere antwoordoptie. Denk hierbij aan de vraag hoeveel kinderen iemand heeft.
Hier kan je een precies antwoord op geven en dit is dus ratio (want je kan ook als antwoordoptie 0
hebben).
Social desirability Je geeft een antwoord waarvan je denkt dat het sociaal geaccepteerd binnen de
bepaalde groep of gemeenschap waarin je je bevindt. Dit is dus niet je echte antwoord, maar het
antwoord dat naar jou mening het meest sociaal wenselijk is in je omgeving.
*Fouten*
Wanneer we een survey maken stellen we veel vragen aan individuele personen (de personen zelf
boeien ons niet persoonlijk). De antwoorden die zij geven zijn niet per se boeiend. We willen vooral
weten of iets iets over de populatie zegt.
Target audience niet de volledige populatie die bestaat, maar de populatie waar JIJ iets over
zeggen wil!
Bij surveys interviewen we NOOIT iedereen. We interviewen gewoon een random aantal mensen
binnen de populatie.
Voorbeeldsituatie: populatie in de hoorcollegezaal; “hoe vinden jullie de les tot nu toe?”.
De voorste rij is niet representatief als ‘deel’populatie, want er kunnen bijvoorbeeld mensen vooraan
zitten omdat ze en te laat zijn en die de les sowieso niet leuk vinden. Echter kunnen er ook mensen
tussen zitten die juist de les leuk vinden.
Er kan dan bias ontstaan;
- Systematisch positieve bias
- Systematisch negatieve bias
We willen in de survey geen random error en we willen geen bias!
Random error (willekeurige fout) Men weet niet wat je als individueel persoon denkt maar
‘overall’ wordt er verwacht dat er een goede schatting van je mening kan worden gemaakt. Dit kan
niet bij bias; er kan geen goede schatting gemaakt worden van je ‘overall opinion’.
Systematische bias Je bent waarschijnlijk je gemiddelde aan het ‘overestimaten’ of
‘underestimaten’, dus je schat je gemiddelde hoger dan dat het zou moeten zijn of je schat je
gemiddelde lager.
Beide fouten geven je wel wat inzicht, maar het hangt ervan af wat het is en wat het doet.
Random error steekproef is niet representatief
Systematic error bias je geeft een antwoord op een vraag, maar het antwoord is geen goede
reflectie van de status van je echte antwoord.
Beetje vaag, maar stel je vraagt aan iemand: ‘heb je dit gedaan?’ en iemand zegt ‘ja’ maar
het daadwerkelijke antwoord is ‘nee’, dan is er sprake van systematische error bias.
OF Iemand stelt een complexe vraag en je wil het goede antwoord geven, maar je weet niet
hoe! We gaan er dan vanuit dat de gegeven antwoorden representatief zijn voor de
populatie, maar in werkelijkheid is dit niet zo. De fouten zijn dan random verschillend of
systematisch verschillend.
Dusssssss….. kleine samenvatting!
- We hebben random errors, oftewel willekeurige fouten
- En we hebben systematische fouten en deze zijn biased (in theorie goede steekproef;
dus representatief; maar we hebben gewoon geen geluk binnen de resultaten (ze zijn
niet representatief))
Random error
- Steekproef fout
- Vragen: (invalide vragen) Invaliditeit, ‘het was een eerlijke fout’
, Stel: je vraagt aan een groep mensen hoeveel liedjes ze per dag luisteren. De ene groep geeft
een te hoog antwoord en een andere een te laag antwoord omdat ze het correcte antwoord
gewoon niet weten. Een andere groep geeft wel het juiste antwoord omdat ze dit laatst
opgezocht hebben. Dan kloppen de resultaten voor het individu niet, maar er valt wel een
schatting te maken over het aantal liedjes over de gehele populatie.
Is dit erg? Nee, niet als je iets wil weten over de gehele populatie.
Systematische bias fout
- Steekproef bias (voorbeeld van de studenten die voorin zitten die bijvoorbeeld ofwel
positief ofwel negatief biased zijn)
- Vragen: bias: ‘heb je dit gedaan?’, antwoord is nee, maar je zegt ja
‘Over rapporteren’, want omdat de leraar het bijvoorbeeld vraagt, wordt er vaker ja
gerapporteerd dan daadwerkelijk zou moeten (social desirability, komt verder nog aan bod).
*De manier waarop je een vraag stelt, of de persoon die vraag stelt heeft invloed op de ‘validity’ van
de antwoorden die je krijgt.*
*Vragen stellen*
Meerdere soort fouten vragen:
- Two barreled questions Er worden eigenlijk twee vragen gesteld binnen een vraag; ‘Is
dit een leuk en interessant vak?’.
- Leidende (BIASED) vragen Vragen die je al een bepaalde richting in sturen; ‘Vind jij
ook dat de vaccinatieplicht afgeschaft moet worden?’.
Veelvoorkomende fouten omtrent vragen in surveys:
- Een vraag die gesteld wordt met de verkeerde woorden
- De manier waarop de vraag gesteld wordt door de interviewer
- Iets wordt niet begrepen door degene die geïnterviewd wordt: hebben mensen
bijvoorbeeld wel de kennis om een vraag te beantwoorden bedenken doelgroep
- De geïnterviewde kan sommige dingen niet meer herinneren
- De manier hoe informatie door de interviewer wordt vastgelegd
- De manier hoe informatie wordt verwerkt; dus de manier hoe antwoorden worden
gecodeerd of hoe data in de computer wordt gezet
- Als je simpele, korte antwoorden wil, moet je de vragen ook simpel houden
‘I don’t know’ – optie
- Je kan er niet zomaar vanuit gaan dat mensen die ‘don’t know’ aanklikken in de survey
random verdeeld worden over de andere factoren. De mensen die dit aanklikken zijn dus
niet gelijk verdeeld over de antwoord opties. Je kan er niet vanuit gaan dat als je de optie
weglaat, je dezelfde verdeling krijgt als wanneer je de optie niet weg zou laten!
- Deze optie wordt vaak gekozen, omdat het een makkelijke optie is. Je hoeft er minder
over na te denken als de vraag wat moeilijker is (dit geldt ook voor de ‘middelcategorie’).
Wie kiest er eigenlijk voor deze optie??
- Iets kan cultureel gevoelig zijn.. Stel iemand stelt een vraag en jij geeft een ander
antwoord dan ‘I don’t know’, omdat je diegene wil helpen, kan dit fout zijn als het echte
antwoord wel ‘I don’t know’ is. Wat ook meeweegt hierbij is of de survey online is of
face-to-face.
- Onderwijsniveau kan invloed hebben in de mate waarmee er met de optie geantwoord
wordt; mensen met een hoog niveau zullen vaker deze optie gebruiken. Ze weten
namelijk vaak wat ze wel en juist niet weten!
, Soms is het handig om een middelcategorie te hebben. Mensen zeggen vaak dat het eigenlijk een
‘geen mening’ optie is. Wanneer je middeloptie in de survey stopt, wordt de ‘don’t know’- optie ook
minder gebruikt.
Don’t know optie wel of niet implementeren in survey????
- Als je wil dat mensen echt een keuze maken (omdat ze ook echt weten welke keuze ze
moeten maken; voorbeeld: poets je je tanden altijd twee keer per dag) NIET;
- Als je wil dat mensen een keuze maken alleen als ze dat ook echt kunnen (soms is het
handig om wel een extra optie in de survey te doen, omdat dit dan een goed antwoord
is) WEL!
Beware:
- Als je geen middeloptie toevoegt, kan er irritatie ontstaan doordat mensen oprecht geen
antwoord hebben op de vraag.
- Middelopties zijn soms ook onvoorspelbaar
*Antwoordopties*
Ordinaal Totally agree, agree, disagree, totally disagree
Ordinaal Agree ……….. Disagree
Maaaaaaaaarrrr… De laatste behandelen we als interval (Het heeft namelijk meer dan zeven
antwoordcategorieen). Je kan namelijk als alle vragen dezelfde karakteristieken hebben; dus allemaal
5 punts-Likertschaal bijvoorbeeld; een variabele maken op intervalniveau.
Ratio Bijvoorbeeld: ‘Hoe vaak ga je naar de bar?’ (voeg hierbij een tijdsperiode toe, dus
bijvoorbeeld ‘per week’ of per maand’ voor meer duidelijkheid).
--->
Ordinaal Als je de antwoordopties verandert in bijvoorbeeld: Nooit – af en toe – regelmatig – vaak
Een antwoordoptie hoeft niet altijd helemaal precies te zijn. Denk hierbij aan het antwoord op de
vraag hoe vaak iemand naar de bar gaat. Bij ander soort vragen kan er wel gebruik gemaakt worden
van een meer preciezere antwoordoptie. Denk hierbij aan de vraag hoeveel kinderen iemand heeft.
Hier kan je een precies antwoord op geven en dit is dus ratio (want je kan ook als antwoordoptie 0
hebben).
Social desirability Je geeft een antwoord waarvan je denkt dat het sociaal geaccepteerd binnen de
bepaalde groep of gemeenschap waarin je je bevindt. Dit is dus niet je echte antwoord, maar het
antwoord dat naar jou mening het meest sociaal wenselijk is in je omgeving.