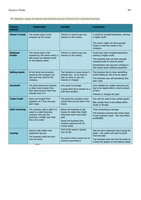
SPSS-samenvatting
Slides:
1. SPSS 1a: Data screening slides (49.57)
2. SPSS 1b: Diagnostics in regression slides (1.14.05)
3. G*power analysis slides (8.06)
4. SPSS 2: PROCES, mediation and moderation analysis (34.27)
5. SPSS 3 and Q&A lecture: ANCOVA (44.35)
6. SPSS 4: rm-ANOVA, mixed ANOVA (1.06.22)
7. SPSS 4: Q&A: Effect sizes > niet als lecture opgenomen
SPSS 1a: Data screening (lecture)
Stappen:
o Levels van de variabelen
o Checken op outliers
o Normaliteit assumptie
o Lineariteit
o Homogenity
o Multicollineariteit
o Checken kwaliteit voorspelling
Outliers detecteren:
1. Het bekijken van graphs:
o Univariate: Via een histogram kan je
zien of er outliers zijn (vb. helemaal
links of rechts). Dit kan je voor alle
continue variabelen doen.
o Bivariate: Wanneer je naar meerdere
variabelen met elkaar wil bekijken, kan
je bijvoorbeeld plotten. Je zet dan de
ene tegen de andere neer. Via Graphs > Legacy dialogs > scatterplot. Deze
bivariate analyse is handiger om te bekijken, omdat je hier outliers kan ontdekken
die je bijvoorbeeld niet zou zijn als je beide variabelen apart zou bekijken in een
histogram (univariate).
, 2. Outliers in Y-ruimte (alleen afhankelijke variabelen):
standardized residuals. Regel dat het tussen -3 en 3 ligt.
Een standardized variabele is een z-score. Value min de
gemiddelde gedeeld door de standaarddeviatie. Voor
alle variabelen kan hetzelfde geïnterpreteerd worden
tot de afstand tot de gemiddelden. Descriptives > vink
‘save standardized values as variables’ aan. De
standardized residuals zijn de error voor elke meting in
het design. Een grote residual vertelt dat deze ‘case’
niet goed voorspeld is. Met de z-scores kun je dat
interpreteren via een analyse.
Regression > lineair > ‘save’ >
‘Cook’s’ en ‘Mahalanobis’ aan
en ‘standardized residuals’.
Hiermee krijg je een tabel met
‘residuals statistics’. Kijk in de
tabel bij ‘std. Residual’, als er bij
minimum of maximum een groot aantal staat, bijvoorbeeld bij 3.110, dan dien je er
nog eens naar te kijken. Door de Cooks en mahalanobis aan te zetten kan je ook punt
3 en 4 toetsen. ‘Are cause for concern’ betekent dat je het moet evalueren, maar niet
direct dat je ze moet verwijderen. Om de residuals te bekijken kan je statistics
bekijken waarin je de verschillende waarden zien met de percentages en dergelijke
(zie rechter afbeelding). Mahalanobis gaat altijd om de onafhankelijke variabele en
cook’s distance gaat altijd over het hele model XY.
3. Outliers in X-ruimte: Mahalanobis distance laat zien of er een outlier is op je
onafhankelijke variabelen in de X-ruimte. Kijkt niet naar afhankelijke variabelen.
Mahalanobis controleert op outliers op voorspellende variabelen.
o Bij n=500 zou mahalanobis <20-25 moeten zijn.
o Bij n=100 zou Mahalanobis <15 moeten zijn.
o Bij n=30, zou mahalanobis <11 moeten zijn.
4. Outliers in XY-ruimten (beide onafhankelijke en afhankelijke variabelen): Cook’s
distance. Regel: Cook’s distance <1. Cook’s distance is een algemene maatstaf voor
de invloed van een punt op de waarden van de regressiecoëfficiënt
Assumptie normaliteit: via een histogram bekijken en q-q-plot. Via descriptives > q-q-
plot. Normaal doe je de q-q-plot niet op de afhankelijke variabelen, maar op de residuals
(erg belangrijk!). Als de data normaalverdeeld is, zou het op de lijn moeten liggen. Als ze
systematisch onder en boven de lijn liggen, is het een sterke indicatie voor niet-
normaliteit. We hebben altijd gehoord dat de afhankelijke variabele normaal verdeeld
moeten zijn, maar in feiten dient de error van het model normaal verdeeld te zijn. Dus
een residual aanmaken via lineaire regressie en dan daarmee histogram maken.
Wanneer is het checken van
normaliteit echt nodig? Soms
wordt er gezegd dat minimaal
dertig mensen per groep nodig
hebt om iets te zeggen over de
residuals, maar het is meer
Slides:
1. SPSS 1a: Data screening slides (49.57)
2. SPSS 1b: Diagnostics in regression slides (1.14.05)
3. G*power analysis slides (8.06)
4. SPSS 2: PROCES, mediation and moderation analysis (34.27)
5. SPSS 3 and Q&A lecture: ANCOVA (44.35)
6. SPSS 4: rm-ANOVA, mixed ANOVA (1.06.22)
7. SPSS 4: Q&A: Effect sizes > niet als lecture opgenomen
SPSS 1a: Data screening (lecture)
Stappen:
o Levels van de variabelen
o Checken op outliers
o Normaliteit assumptie
o Lineariteit
o Homogenity
o Multicollineariteit
o Checken kwaliteit voorspelling
Outliers detecteren:
1. Het bekijken van graphs:
o Univariate: Via een histogram kan je
zien of er outliers zijn (vb. helemaal
links of rechts). Dit kan je voor alle
continue variabelen doen.
o Bivariate: Wanneer je naar meerdere
variabelen met elkaar wil bekijken, kan
je bijvoorbeeld plotten. Je zet dan de
ene tegen de andere neer. Via Graphs > Legacy dialogs > scatterplot. Deze
bivariate analyse is handiger om te bekijken, omdat je hier outliers kan ontdekken
die je bijvoorbeeld niet zou zijn als je beide variabelen apart zou bekijken in een
histogram (univariate).
, 2. Outliers in Y-ruimte (alleen afhankelijke variabelen):
standardized residuals. Regel dat het tussen -3 en 3 ligt.
Een standardized variabele is een z-score. Value min de
gemiddelde gedeeld door de standaarddeviatie. Voor
alle variabelen kan hetzelfde geïnterpreteerd worden
tot de afstand tot de gemiddelden. Descriptives > vink
‘save standardized values as variables’ aan. De
standardized residuals zijn de error voor elke meting in
het design. Een grote residual vertelt dat deze ‘case’
niet goed voorspeld is. Met de z-scores kun je dat
interpreteren via een analyse.
Regression > lineair > ‘save’ >
‘Cook’s’ en ‘Mahalanobis’ aan
en ‘standardized residuals’.
Hiermee krijg je een tabel met
‘residuals statistics’. Kijk in de
tabel bij ‘std. Residual’, als er bij
minimum of maximum een groot aantal staat, bijvoorbeeld bij 3.110, dan dien je er
nog eens naar te kijken. Door de Cooks en mahalanobis aan te zetten kan je ook punt
3 en 4 toetsen. ‘Are cause for concern’ betekent dat je het moet evalueren, maar niet
direct dat je ze moet verwijderen. Om de residuals te bekijken kan je statistics
bekijken waarin je de verschillende waarden zien met de percentages en dergelijke
(zie rechter afbeelding). Mahalanobis gaat altijd om de onafhankelijke variabele en
cook’s distance gaat altijd over het hele model XY.
3. Outliers in X-ruimte: Mahalanobis distance laat zien of er een outlier is op je
onafhankelijke variabelen in de X-ruimte. Kijkt niet naar afhankelijke variabelen.
Mahalanobis controleert op outliers op voorspellende variabelen.
o Bij n=500 zou mahalanobis <20-25 moeten zijn.
o Bij n=100 zou Mahalanobis <15 moeten zijn.
o Bij n=30, zou mahalanobis <11 moeten zijn.
4. Outliers in XY-ruimten (beide onafhankelijke en afhankelijke variabelen): Cook’s
distance. Regel: Cook’s distance <1. Cook’s distance is een algemene maatstaf voor
de invloed van een punt op de waarden van de regressiecoëfficiënt
Assumptie normaliteit: via een histogram bekijken en q-q-plot. Via descriptives > q-q-
plot. Normaal doe je de q-q-plot niet op de afhankelijke variabelen, maar op de residuals
(erg belangrijk!). Als de data normaalverdeeld is, zou het op de lijn moeten liggen. Als ze
systematisch onder en boven de lijn liggen, is het een sterke indicatie voor niet-
normaliteit. We hebben altijd gehoord dat de afhankelijke variabele normaal verdeeld
moeten zijn, maar in feiten dient de error van het model normaal verdeeld te zijn. Dus
een residual aanmaken via lineaire regressie en dan daarmee histogram maken.
Wanneer is het checken van
normaliteit echt nodig? Soms
wordt er gezegd dat minimaal
dertig mensen per groep nodig
hebt om iets te zeggen over de
residuals, maar het is meer