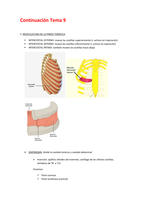
BEGRIP UITLEG
Kwalitatief onderzoek • Mensen in hun natuurlijke omgeving
bestuderen
• Holistische aanpak
• Interviews, focus groepen, tekst analyses
Correlationeel onderzoek • Kwantitatief
• Verbanden tussen variabelen bestuderen
• Moeilijk om causaliteit te onderzoeken
Experimenteel onderzoek • Manipulatie door onderzoeker
• Vergelijkt experimentele groep met controle
groep
• Kwantitatieve metingen
• Geschikt voor causaal onderzoek
Organische gegevens Toevallig gegenereerde data
• Aspirationele data Data die we genereren omdat wij als mensen dat willen (alles op
social media wordt gegenereerd omdat wij de beslissing nemen om
iets te delen)
• Transactionele data Data die gegenereerd wordt via transacties, via je bankpas /
bonuskaart
Ontworpen / designed gegevens Gegevens die doelgericht zijn gegenereerd
• Experiment
• Survey
• Administratief (via bv. Belastingdienst)
Inferentiële doelen 1. Beschrijven
2. Causaliteit
3. Voorspellen
Soorten surveys • Face-to-face (CAPI)
• Vragenlijst die per post komt
• Telefonisch (CATI)
• Via het internet
• Mixed modes
Cross-sectioneel onderzoek Hierbij verzamel je informatie van veel individuen op één
moment in de tijd (kan wel eens per jaar uitgevoerd worden =
panelonderzoek)
Voordelen • We kunnen binnen-persoon verandering &
causaliteit meten
• We kunnen leeftijds-, periode en cohort
effecten verklaren
(effecten binnen verschillende generaties)
Nadelen • Verloop (= uitval)
• Panel conditionering (leereffecten = elke
maand dezelfde vragenlijst)
,Conceptuele definitie Een duidelijke definitie van wat de onderzoeker bedoeld met
een bepaald theoretisch concept
Operationele definitie Hoe gaat de onderzoeker dit begrip meten
Variabele maken uit testscores 1. Alle itemscores bij elkaar optellen
2. OF het gemiddelde berekenen van alle
itemscores
Ompolen Het omdraaien van omgekeerd geformuleerde items
Betrouwbare meting De meting varieert niet door kenmerken van a) de manier
(consistentie) waarop je hebt gemeten of b) het meetinstrument
Valide meting Hoe goed je meting overeenkomt met het theoretische begrip
(nauwkeurigheid) waarin je geïnteresseerd bent
Begripsvaliditeit • Indruk: lijkt de meting in orde?
• Inhoud: meet het alle aspecten van het
construct?
• Convergent: correleert het met een andere
meting van hetzelfde construct?
• Divergent: correleert het niet met iets dat iets
anders meet?
• Criterium: correleert het niet met een andere
meting waarvan we weten dat de relatie er is?
Correlatie Een maat voor het meten van de sterkte en richting van een
lineaire relatie tussen twee interval-/ ratiovariabelen
• Aangegeven met R
• Waarden tussen -1 en +1
Test-hertest betrouwbaarheid Dezelfde vragenlijst op een later tijdstip aan dezelfde groep
mensen nog een keer geven
Interbeoordelaarsbetrouwbaarheid Vooral bij observaties. Als meerdere mensen hetzelfde
observeren zullen ze vergelijkbare resultaten moeten hebben.
• Gemeten a.d.h.v. Cronbach's alpha
• Meet dus interne In welke mate zijn de items in een vragenlijst met elkaar
consistentie gecorreleerd?
Cronbach's alpha Varieert van 0 tot 1, bij 0 geen relatie bij 1 veel relatie
Over het algemeen:
• Alpha < 0,7 = goed
• Alpha > 0,8 = slecht
Item-rest correlatie Meet in elke rij de correlatie tussen die vraag en een
schaalscore gemaakt uit alle andere vragen. Een lage correlatie
betekent dat deze vraag niet goed samenhangt met de rest van
de vragen.
• Vuistregel: rit < +- 0.2 --> item kan mogelijk worden
verwijderd
, "If item dropped Cronbach's alpha" Als we deze vraag weghalen wat zou er dan gebeuren met de
Cronbach's alpha (oftewel interne betrouwbaarheid)
• Vuistregel: alpha neemt het meeste toe --> item kan als
eerste worden verwijderd
!!Je mag maar 1 item tegelijk verwijderen!!
Stappen variabele creëren 1. Ompolen van items
2. Betrouwbaarheidsanalyse
3. Schaalscore berekenen
Regressie Wordt gebruikt om:
(=voorspellingen) • De lineaire relatie te beschrijven met een
vergelijking
• Voorspellingen te doen met behulp van deze
vergelijking
Afhankelijke variabele (in regressie) De variabele die wordt voorspeld
• Wordt aangegeven met Y
Onafhankelijke variabele De variabele die gebruikt wordt om voorspellingen te doen
• Wordt aangegeven met X
Residu Het verschil tussen een punt op de lijn (die we gebruiken om
voorspellingen te doen) en de observatie, echte waarde, van
die persoon
• De grootte van de residuen is een soort van maat van
hoe goed die lijn bij de dataset past
Least squares regression De kwadraten van alle residuen worden bij elkaar opgeteld. De
vergelijking met de kleinste som van de gekwadrateerde
residuen is de winnaar
Als er weinig spreiding is rond de • Zijn de meeste residuen klein
regressielijn, dan…. • Zullen de voorspellingen met de
regressievergelijking zeer nauwkeurig zijn
Als er meer spreiding is rond de • Zijn de residuen over het algemeen groter
regressielijn, dan…. • Zullen de voorspellingen met de
regressievergelijking minder nauwkeurig zijn
Standaardschattingsfout Een maat voor de nauwkeurigheid van de voorspellingen
• De standaardafwijking van de residuen
• Grofweg de gemiddelde grootte van de fouten die we
maken als we de regressievergelijkingen gebruiken om
voorspellingen te doen
Regressievergelijking
(Y dakje geeft in de statistiek aan dat het een schatting is)
• B1 geeft dus aan hoe stijl de lijn is = hellingsgetal
• H0 --> als er niks is, geen relatie tussen deze variabelen
Kwalitatief onderzoek • Mensen in hun natuurlijke omgeving
bestuderen
• Holistische aanpak
• Interviews, focus groepen, tekst analyses
Correlationeel onderzoek • Kwantitatief
• Verbanden tussen variabelen bestuderen
• Moeilijk om causaliteit te onderzoeken
Experimenteel onderzoek • Manipulatie door onderzoeker
• Vergelijkt experimentele groep met controle
groep
• Kwantitatieve metingen
• Geschikt voor causaal onderzoek
Organische gegevens Toevallig gegenereerde data
• Aspirationele data Data die we genereren omdat wij als mensen dat willen (alles op
social media wordt gegenereerd omdat wij de beslissing nemen om
iets te delen)
• Transactionele data Data die gegenereerd wordt via transacties, via je bankpas /
bonuskaart
Ontworpen / designed gegevens Gegevens die doelgericht zijn gegenereerd
• Experiment
• Survey
• Administratief (via bv. Belastingdienst)
Inferentiële doelen 1. Beschrijven
2. Causaliteit
3. Voorspellen
Soorten surveys • Face-to-face (CAPI)
• Vragenlijst die per post komt
• Telefonisch (CATI)
• Via het internet
• Mixed modes
Cross-sectioneel onderzoek Hierbij verzamel je informatie van veel individuen op één
moment in de tijd (kan wel eens per jaar uitgevoerd worden =
panelonderzoek)
Voordelen • We kunnen binnen-persoon verandering &
causaliteit meten
• We kunnen leeftijds-, periode en cohort
effecten verklaren
(effecten binnen verschillende generaties)
Nadelen • Verloop (= uitval)
• Panel conditionering (leereffecten = elke
maand dezelfde vragenlijst)
,Conceptuele definitie Een duidelijke definitie van wat de onderzoeker bedoeld met
een bepaald theoretisch concept
Operationele definitie Hoe gaat de onderzoeker dit begrip meten
Variabele maken uit testscores 1. Alle itemscores bij elkaar optellen
2. OF het gemiddelde berekenen van alle
itemscores
Ompolen Het omdraaien van omgekeerd geformuleerde items
Betrouwbare meting De meting varieert niet door kenmerken van a) de manier
(consistentie) waarop je hebt gemeten of b) het meetinstrument
Valide meting Hoe goed je meting overeenkomt met het theoretische begrip
(nauwkeurigheid) waarin je geïnteresseerd bent
Begripsvaliditeit • Indruk: lijkt de meting in orde?
• Inhoud: meet het alle aspecten van het
construct?
• Convergent: correleert het met een andere
meting van hetzelfde construct?
• Divergent: correleert het niet met iets dat iets
anders meet?
• Criterium: correleert het niet met een andere
meting waarvan we weten dat de relatie er is?
Correlatie Een maat voor het meten van de sterkte en richting van een
lineaire relatie tussen twee interval-/ ratiovariabelen
• Aangegeven met R
• Waarden tussen -1 en +1
Test-hertest betrouwbaarheid Dezelfde vragenlijst op een later tijdstip aan dezelfde groep
mensen nog een keer geven
Interbeoordelaarsbetrouwbaarheid Vooral bij observaties. Als meerdere mensen hetzelfde
observeren zullen ze vergelijkbare resultaten moeten hebben.
• Gemeten a.d.h.v. Cronbach's alpha
• Meet dus interne In welke mate zijn de items in een vragenlijst met elkaar
consistentie gecorreleerd?
Cronbach's alpha Varieert van 0 tot 1, bij 0 geen relatie bij 1 veel relatie
Over het algemeen:
• Alpha < 0,7 = goed
• Alpha > 0,8 = slecht
Item-rest correlatie Meet in elke rij de correlatie tussen die vraag en een
schaalscore gemaakt uit alle andere vragen. Een lage correlatie
betekent dat deze vraag niet goed samenhangt met de rest van
de vragen.
• Vuistregel: rit < +- 0.2 --> item kan mogelijk worden
verwijderd
, "If item dropped Cronbach's alpha" Als we deze vraag weghalen wat zou er dan gebeuren met de
Cronbach's alpha (oftewel interne betrouwbaarheid)
• Vuistregel: alpha neemt het meeste toe --> item kan als
eerste worden verwijderd
!!Je mag maar 1 item tegelijk verwijderen!!
Stappen variabele creëren 1. Ompolen van items
2. Betrouwbaarheidsanalyse
3. Schaalscore berekenen
Regressie Wordt gebruikt om:
(=voorspellingen) • De lineaire relatie te beschrijven met een
vergelijking
• Voorspellingen te doen met behulp van deze
vergelijking
Afhankelijke variabele (in regressie) De variabele die wordt voorspeld
• Wordt aangegeven met Y
Onafhankelijke variabele De variabele die gebruikt wordt om voorspellingen te doen
• Wordt aangegeven met X
Residu Het verschil tussen een punt op de lijn (die we gebruiken om
voorspellingen te doen) en de observatie, echte waarde, van
die persoon
• De grootte van de residuen is een soort van maat van
hoe goed die lijn bij de dataset past
Least squares regression De kwadraten van alle residuen worden bij elkaar opgeteld. De
vergelijking met de kleinste som van de gekwadrateerde
residuen is de winnaar
Als er weinig spreiding is rond de • Zijn de meeste residuen klein
regressielijn, dan…. • Zullen de voorspellingen met de
regressievergelijking zeer nauwkeurig zijn
Als er meer spreiding is rond de • Zijn de residuen over het algemeen groter
regressielijn, dan…. • Zullen de voorspellingen met de
regressievergelijking minder nauwkeurig zijn
Standaardschattingsfout Een maat voor de nauwkeurigheid van de voorspellingen
• De standaardafwijking van de residuen
• Grofweg de gemiddelde grootte van de fouten die we
maken als we de regressievergelijkingen gebruiken om
voorspellingen te doen
Regressievergelijking
(Y dakje geeft in de statistiek aan dat het een schatting is)
• B1 geeft dus aan hoe stijl de lijn is = hellingsgetal
• H0 --> als er niks is, geen relatie tussen deze variabelen