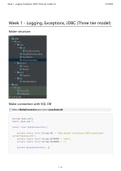
12. Statistik MULTIVARIATE DATENREIHEN
PRE-MAßE IN DER NOMINALSKALA
PRE-Maße (proportional reduction of error):
Völlig andere, sehr allgemeine Grundidee zur Beschreibung von Zusammenhängen.
• Grundlegendes Prinzip vieler statistischer Konzepte.
• Hängt mit Streuungszerlegung metrischer Daten zusammen.
• Anwendbar für Kreuztabellen beliebiger Größe.
• In der Soziologie und Psychologie gebräuchlich, da das Prinzip auf sehr viele unterschiedliche Situationen
anwendbar ist.
Man schaut sich an, wie viele Fehler man bei der Vorhersage der AV ohne Kenntnis der UV macht und wie viele
Fehler mit Kenntnis der UV. Dazu braucht man eine Fehlerdefinition (Anzahl falsche Zuordnungen in der
Häufigkeitstabelle). Man vergleicht das Verhältnis beider Fehler. Pre-Maße gibt es für alle Skalenniveaus, wir
behandeln das Maß für Nominalskalenniveau: Goodmans und Kruskals Lambda.
PRE = Proportional Reduction in Error
𝑃𝑅𝐸 = 𝐸1 − 𝐸2
𝐸1
=1− 𝐸2
𝐸1
wobei E1 und E2 als Vorhersagefehler definiert sind
PRE ist automatisch auf [0; 1] normiert, es gilt automatisch 𝐸2 ≤ 𝐸1:
• PRE = 1 gilt genau dann wenn E2 = 0, d.h. bei vollständiger Vorhersage bzw. vollständigem Zusammenhang. • PRE =
0 gilt genau dann wenn E1 = E2, d.h. die Vorhersage wird durch Kenntnis der unabhängigen Variablen in keiner
Weise unterstützt, d.h. es besteht kein Zusammenhang.
• Für nominalskalierte Daten benutzen wir Goodmans und Kruskals Lambda
Lernzeit kurz mittel lang Summe
Einkommen
niedrig
mittel
hoch
Summe
Beispiel: Hypothese: Nach langer Lernzeit im Beruf steigt das Einkommen
PRE-MAßE IN DER NOMINALSKALA
PRE-Maße (proportional reduction of error):
Völlig andere, sehr allgemeine Grundidee zur Beschreibung von Zusammenhängen.
• Grundlegendes Prinzip vieler statistischer Konzepte.
• Hängt mit Streuungszerlegung metrischer Daten zusammen.
• Anwendbar für Kreuztabellen beliebiger Größe.
• In der Soziologie und Psychologie gebräuchlich, da das Prinzip auf sehr viele unterschiedliche Situationen
anwendbar ist.
Man schaut sich an, wie viele Fehler man bei der Vorhersage der AV ohne Kenntnis der UV macht und wie viele
Fehler mit Kenntnis der UV. Dazu braucht man eine Fehlerdefinition (Anzahl falsche Zuordnungen in der
Häufigkeitstabelle). Man vergleicht das Verhältnis beider Fehler. Pre-Maße gibt es für alle Skalenniveaus, wir
behandeln das Maß für Nominalskalenniveau: Goodmans und Kruskals Lambda.
PRE = Proportional Reduction in Error
𝑃𝑅𝐸 = 𝐸1 − 𝐸2
𝐸1
=1− 𝐸2
𝐸1
wobei E1 und E2 als Vorhersagefehler definiert sind
PRE ist automatisch auf [0; 1] normiert, es gilt automatisch 𝐸2 ≤ 𝐸1:
• PRE = 1 gilt genau dann wenn E2 = 0, d.h. bei vollständiger Vorhersage bzw. vollständigem Zusammenhang. • PRE =
0 gilt genau dann wenn E1 = E2, d.h. die Vorhersage wird durch Kenntnis der unabhängigen Variablen in keiner
Weise unterstützt, d.h. es besteht kein Zusammenhang.
• Für nominalskalierte Daten benutzen wir Goodmans und Kruskals Lambda
Lernzeit kurz mittel lang Summe
Einkommen
niedrig
mittel
hoch
Summe
Beispiel: Hypothese: Nach langer Lernzeit im Beruf steigt das Einkommen